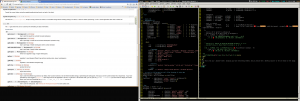
AWS Lambda is one of those technologies that makes the distinction between infrastructure and application code quite blurry. There are many frameworks out there, some of them quite popular, such as AWS Amplify and the Serverless Framework, which will allow you to define your Lambda, your application code, and will provide tools that will package and provision, and then deploy those Lambdas (using CloudFormation under the hood). They also provide tools to locally run the functions for local testing, which is particularly useful if they are invoked using technologies such as API Gateway. Sometimes, however, especially if your organisation has adopted other Infrastructure as Code tools such as Terraform, you might want to just provision a function with simpler IaC tools, and keep the application deployment steps separate. Let us explore an alternative method to still be able to run and test API Gateway based Lambdas locally without the need to bring in big frameworks such as the ones mentioned earlier.
Ah, those good, old flaky test suites! Sooner or later you’ll encounter one of them. They are test suites that sometimes pass, sometimes fail, depending on certain environmental conditions. A lot has been written about flaky tests and what causes them, but in this post I’d like to discuss a specific type of flaky test –order dependant test failures–, and how to help debug them using GitHub Actions as part of your CI/CD pipelines.
Sidekiq has recently been updated to major version 6, and it includes a bunch of new and interesting features. One that resonated a lot with me was the ability to log in JSON format by default, which is now possible thanks to the newly refactored set of classes that handle logging in the library.
Let’s have a quick look at how to use the new API to do something slightly controversial: logging job arguments.
I've been willing to give the serverless framework a try for a while, and recently I came up with a small side project that was a potential good fit for it.
I am a Monzo user, and I use their card to pay for things like my weekday lunches around the office or my travel expenses like Oyster Card top ups. I also happen to be a user of Toshl, which helps me with my personal finances and budgets.
Typically, whenever my Oyster card gets topped up or I pay for a lunch in a restaurant, I then input that expense into Toshl. But turns out both Monzo and Toshl are developer friendly, so I thought I could easily automate that process by having a system that would get certain Monzo expenses directly into Toshl for me, saving me a few seconds per day.
A serverless approach was ideal for this, especially since AWS offers a free tier for its services, meaning this would also not cost me a penny.
In this post we'll learn how to set and delete cookies as part of your Go HTTP Handlers. We'll also learn one way to test our handlers using HTTP recorders.
Microservices everywhere. Those are the times we live in now. Everyone seems to be splitting monolithic web applications into smaller chunks. And that's fine. However, setting up the local development environment for this can be sometimes a bit cumbersome.
I started using Telegram a few years ago. Most of the time I don’t use it much to have 1 to 1 conversations but rather chat in a small group of friends which I’ve known for a while now. Every now and then, we share some links to Twitter on that group, and unfortunately the Telegram official clients preview mode don’t support previewing Twitter messages with more than one image.
The moment I link this to a Telegram chat, this is the result:
Which is not ideal, as sometimes the message doesn’t make much sense when only one of the images is displayed.
Turns out I’ve been learning some Go over the last few months as well, so I wondered if I could write a small Telegram Bot to help me with that. I needed something to which I could send a Twitter link, and gave me back either the default Twitter preview in Telegram, or a custom made one with all the images of the message, in case there were more than one.
Here’s a small jQuery code snippet that you can use to have an easy to use checkbox toggler to enable or disable a TinyMCE editor with ease (tested on TinyMCE version 4 and jQuery version 2.1.1).
It’s really easy to use. You just need to create a checkbox element with the class tiny_mce_toggler and a data attribute with the key editor and the text area id used as a TinyMCE editor as a value. The snippet can be easily extracted if you want to use it differently.
In this quite extensive post I will walk you through the process of creating from scratch a box in EC2 ready to use for deploying your Rails app using Ansible. In the process I will show how to write a simple module that, while not necessary, will illustrate some points as well.
If you’ve ever had to do a huge mysql import, you’ll probably understand the pain of not being able to know how long it will take to complete.
At work we use the backup gem to store daily snapshots of our databases, the main one being several gigabytes in size. This gem basically does a mysqldump with configurable options and takes care of maintaining a number of old snapshots, compressing the data and sending notifications on completion and failure of backup jobs.
When the time comes to restore one of those backups, you are basically in the situation in which you simply have to run a mysql command with the exported sql file as input, which can take ages to complete depending on the size of the file and the speed of the system.
The command used to import the database snapshot from the backup gem may look like this:
What this command does is untar the gzipped file and sending it as an input to a mysql command to the database you want to restore (passing it through zcat before to gunzip it).
And then the waiting game begins.
There is a way, though, to get an estimate of the amount of work already done, which may be a big help for the impatiens like myself. You only need to make use of the good proc filesystem on Linux.
The first thing you need to do is find out the tar process that you just started:
ps ax | grep"database_snapshot\.tar" | grep-vgrep
This last command assumes that no other processes will have that string on their invocation command lines.
We are really interested in the pid of the process, which we can get with some unix commands and pipes, appending them to the last command:
This will basically get the last line of the process list output (with tail), separate it in fields using the space as a delimiter and getting the first one (cut command). Note that depending on your OS and the ps command output you may have to tweak this.
After we have the pid of the tar process, we can see what it is doing on the proc filesystem. The information we are interested in is the file descriptors it has open, which will be in the folder /proc/pid/fd. If we list the files in that folder, we will get an output similar to this one:
The useful part of this list is the pos field. This field is telling us in which position of the file the process is now on. Since tar processes the files sequentially, having this position means we know how much percentage of the file tar has processed so far.
Now the only thing we need to do is check the original file size of the tar file and divide both numbers to get the percentage done.
To get the pos field we can use some more unix commands:
cat /proc/7719/fdinfo/3 | head-n1 | cut-f 2
To get the original file size, we can use the stat command:
stat-c %s /path/to/database_snaphot.tar
Finally we can use bc to get the percentage by just dividing both values:
We have been doing a painful migration from Rails 2 to Rails 3 for several months at work, and refactoring some code the other day I had to do something in a non straightforward way, so I thought I’d share that.
Basically we had an action that would group several files into a zip file and return those zipped files to the user as a response. In the old code, a randomly named file was created on the /tmp folder of the hosting machine, being used as the zip file for the rubyzip gem, and then returned in the controller response as an attachment.
During the migration, we’ve replaced all those bespoken temp file generation for proper Tempfile objects. This was just another one of those replacements to do. But it turned out not to be that simple.
My initial thought was that something like this would do the trick:
filename='attachment.zip'temp_file=Tempfile.new(filename)Zip::File.open(temp_file.path,Zip::File::CREATE)do|zip_file|#put files in hereendzip_data=File.read(temp_file.path)send_data(zip_data,:type=>'application/zip',:filename=>filename)
But it did not. The reason for that is that the open method, when used with the Zip::File::CREATE flag, expects the file either not to exist or to be already a zip file (that is, have the correct zip structure data on it). None of those 2 cases is ours, so the method didn’t work.
So as a solution, you have to open the temporary file using the Zip::OutputStream class and initialize it so it’s converted to an empty zip file, and after that you can open it the usual way. Here’s a full simple example on how to achieve this:
#Attachment namefilename='basket_images-'+params[:delivery_date].gsub(/[^0-9]/,'')+'.zip'temp_file=Tempfile.new(filename)begin#This is the tricky part#Initialize the temp file as a zip fileZip::OutputStream.open(temp_file){|zos|}#Add files to the zip file as usualZip::File.open(temp_file.path,Zip::File::CREATE)do|zip|#Put files in hereend#Read the binary data from the filezip_data=File.read(temp_file.path)#Send the data to the browser as an attachment#We do not send the file directly because it will#get deleted before rails actually starts sending itsend_data(zip_data,:type=>'application/zip',:filename=>filename)ensure#Close and delete the temp filetemp_file.closetemp_file.unlinkend
If you ever need to use the acts_as_list gem in Rails on a model that uses single table inheritance, here’s the snippet you need to use for the list methods to work if you want the setup done on the base model:
acts_as_list:scope=>[:type]
You’ll need to use the array syntax as neither the string nor the symbol versions will work. The symbol one assumes the column ending in _id, while the string one will simply not allow you to evaluate the current object’s type.
It’d be nice to have a lambda syntax in future versions of the gem so you can inject code into the conditions.
We have been using nagios (more specifically Check_MK) recently at work to get some monitoring information on our CentOS instances. Recently we decided to reprovision all of our EC2 instances to apply several security upgrades. Among the packages upgraded, there was the kernel (which I guess was the cause of our subsequent problems).
After updating all our instances, nagios began to complain about the mount options no being the right ones for the root file system, and started sending critical alarms. The file system was ok, it was mounted without problems and everything was woking fine, but for some reason the mount options had changed after the reprovisioning.
Turns out that Check_MK checks the options in place when it does the initial inventory, and if the options change over time, it issues an alarm. If you face this problem, just do a reinventory of your machines and reload the configuration and restart the service, and it should be fine:
This past weeks we have been doing a massive refactoring of our testing suite at work to set up a nice CI server setup, proper factories, etc. Our tool-belt so far is basically a well known list of Rails gems:
For the CI server we decided to use a third party SaaS as our dev team is small and we don’t have the manpower nor the time to set it up ourselves, and we went for CircleCI, which has given us good results so far (easy to set up, in fact almost works out of the box without having to do anything, it has a good integration with GitHub, it’s reasonably fast, and the guys are continuously improving it and very receptive to client’s feedback).
Back to the post topic, when refactoring the integration tests, we discovered that PayPal decided recently to change the way their development sandbox works, and the tests we had in place broke because of it.
The basic workflow when having to test with PayPal involves a series of steps:
Visit their sandbox page and log in with your testing credentials. This saves a cookie in the browser.
Go back to your test page and do the steps needed to perform a payment using PayPal.
Authenticate again to PayPal with your test buyers account and pay.
Catch the PayPal response and do whatever you need to finish your test.
With the old PayPal sandbox, the login was pretty straightforward as you only needed to find the username and password fields in the login form of the sandbox page, fill them in, click the login button, and that was all. But with the new version it’s not that easy. The new sandbox has no login form at the main page. It has a login button which you have to click, then a popup window is shown with the login form. In there you have to input your credentials and click on the login button. Then this popup window does some server side magic, closes itself and triggers a reload on the main page, which will finally show you as logged in.
There’s probably a POST request that you can automatically do to simplify all this, but PayPal is not known as developer documentation friendly so I couldn’t find it. As a result, we had to modify our Capybara tests to handle this new scenario. As we’ve never worked with pop up windows before I thought it’d be nice to share how we did it in case you need to do something similar.
The basic workflow is as follows:
Open the main PayPal sandbox window.
Click on the login button.
Find the new popup window.
Fill in the form in that new window.
Go back to your main window.
Continue with your usual testing.
This assumes you are using the Selenium driver for Capybara. Here’s the code we used to get this done:
describe"a paypal express transaction",:js=>truedoit"should just work"do# Visit the PayPal sandbox urlvisit"https://developer.paypal.com/"# The link for the login button has no id...find(:xpath,"//a[contains(@class,'ppLogin_internal cleanslate scTrack:ppAccess-login ppAccessBtn')]").click# Here we have to use the driver to find the newly opened window using it's name# We also get the reference to the main window as later on we'll have to go back to itlogin_window=page.driver.find_window('PPA_identity_window')main_window=page.driver.find_window('')# We use this to execute the next instructions in the popup windowpage.within_window(login_window)do#Normally fill in the form and log infill_in'email',:with=>"<your paypal sandbox username>"fill_in'password',:with=>"<your paypal sandbox password>"click_button'Log In'end#More on this sleep latersleep(30)#Switch back to the main window and do the rest of the test in itpage.within_window(main_window)do#Here goes the rest of your testendendend
Now there is an important thing to note on the code above: the sleep(30) call. By now you may have read on hundreds of places that using sleep is not a good practice and that your tests should not rely on that. And that’s true. However, PayPal does a weird thing and this is the only way I could use to make the tests pass. It turns out that after clicking the Log In button, the system does some behind the curtains magic, and after having done that, the popup window closes itself and then triggers a reload on the main page. This reload triggering makes things difficult. If you instruct Capybara to visit your page right after clicking the Log In button, you risk having that reload trigger fired in between, and then your test will fail because the next selector you use will not be found as the browser will be in the PayPal sandbox page.
There are probably better and more elegant ways to get around this. Maybe place a code to re-trigger your original visit if it detects you are still on the PayPal page, etc. Feel free to use the comments to suggest possible solutions to that particular problem.
Some weeks ago the site I work on started having severe outages. It looked like the system was not able to fulfill the incoming requests fast enough, making the passenger queue to grow faster than new requests could be served.
Looking at the rails logs it looked like some Chinese bot was crawling the entire site, including a long list of dynamic pages that took a long time to generate and that are not usually visited. Those pages were not yet cached, so every request went through the rails pipeline. Once you start having the dreadful problem of your passenger queue to grow faster and faster you are usually doomed.
Since you can’t expect some of the malicious bots out there to respect the robots.txt file, I had to filter those requests at the Apache level so they did not even reach the application level. This past few months I’ve been learning a lot of systems administration, basically because it’s us, the developers, who also handle this part of the business.
Since all those requests came from the same user agent, I looked for a simple way to filter the requests based on this criteria. It can be easily done if you use the mod_access Apache module. All you need to do is make use of the Allow and Deny directives. Here’s a simple example to filter the ezooms bot:
<Directory "/home/rails/sites/prod/your_site/current/public">
SetEnvIf User-Agent "ezooms" BlockUA
Order allow,deny
Deny from env=BlockUA
Allow from all
</Directory>
What this piece of code does is very self explanatory. The first line tells Apache to set up an environment variable called BlockUA if the user agent of the request matches the “ezooms” string. Then you tell Apache the order it has to evaluate the access control to the directory: it first has to evaluate the Allow directive, and then the Deny one. After that you set up both directives. Allow from all basically allows everything in. Deny from env=BlockUA denies all requests in which the environment variable BlockUA has been set. Since that variable is set up when the user agent matches our desired string, the config will basically deny access to the application to all requests with the “ezooms” user agent.
This way you can easily protect yourself from basic bot attacks.
tl;dr: make sure you add /usr/local/share/npm/bin to your PATH when installing node.js to be able to access the package binaries.
Developing in Ruby on Rails on a Mountain Lion environment can be a pain. Although it’s a UNIX-like environment, most of the tools created for web development have been made with Linux in mind, and making the switch from a Linux box to Mac OS X is far from harmless.
Anyway, the other day I needed to tweak Bootstrap to make the default grid wider, and instead of using the Bootstrap web site customiser, I decided to download the source code from GitHub and build it myself.
In order to do this, you need node.js and some of the packages that come with it. I’ve never developed or even played with node.js before, so I needed to install it on the computer. And that was fairly easy thanks to homebrew by simply issuing the command brew install node.
After node has been installed you have access to npm, the node package manager. Following the Bootstrap instructions, I installed the necessary packages:
npm install recess connect uglify-js jshint -g
After that I thought I was ready to build Bootstrap, but the make command complained about not being able to find some of the node.js binaries I’ve just installed a minute ago.
The solution to the problem, though, was rather simple. It turns out the default formula for nodejs on homebrew doesn’t tell you the folder in which the node.js binaries will be installed in. Without adding this folder to the path, obviously the system can’t find the files it’s supposed to execute.
Simply add the folder /usr/local/share/npm/bin to your PATH environment variable and you’ll be good to go.
If you use your Mac OS X as a development machine and are a regular user of the shell, chances are you are going to be using the movement commands a lot. Chances are, too, that you are using iTerm instead of the system provided Terminal app.
Using the arrow keys is usually enough, but more often than not you need to move between words. This movements, unless you redefine it in your global or local bashrc profile (or any similar shell you maybe using), are done with the keys b and f. Pressing C-b or C-f moves the cursor one character back or forward. Doing if with M-b or M-f does the same but with a word (if you are an Emacs user you will be familiar with those key shortcuts).
The C stands for control key, while the M stands for meta key. In most keyboards (or keymaps to be precise), the control key is mapped to the ctrl key and the meta key is mapped to the alt key. In Mac OS X, the meta key is mapped to the alt key, but as you may very well know, this alt key is known as the option key, and has its peculiarities.
Now, if you open a shell in iTerm and press C-b or C-f, the output will be as expected, but not if you press M-b or M-f. Instead of moving forward or backward a word, you will see that some weird character is written on the command line.
Fortunately this is really easy to fix in iTerm. You just need to go to the Profiles menu, edit your profile (which is most likely to be the default one), and then go to the keys tab. Now, on the bottom of the keymap lists, you will see that you can configure the behaviour of the option key. Set it up to the last option (+Esc) as shown in the screenshot, and then the alt key in iTerm will be sending the shell the adequate escape sequence so all meta mappings work as expected.
iTerm profile editor
EDIT (30/11/2012): looks like this breaks some of the characters that are used by typing the meta key, i.e. the # character (meta + 3). Another way to achieve what we want is to manually map all the meta key shortcuts. This can be done in the same window as before. Select Normal instead of +Esc and, for each key shortcut you want to map, click on the + button. On the opening dialog, type the combination you want to map, for example alt + d, and select Send escape sequence from the drop down Then on the last textbox insert the escape sequence character you want to send (typically the same pressed along the meta key).
Select Send Escape SequenceType the character to send
Well, here it is. This is not a tech post. Not a programming post either. This is just a rant I really needed to put online for some people to know. Also, I know this will never appear on Hacker News but I always wanted to write one of those “why I <type here a randomly shit nobody really cares about>” posts :)
tl;dr: Apple are a bunch of jokers.
Here’s the story. Last week my MacBook decided to refuse booting. It’s a late 2008 model (the first Unibody), and I was hoping it wasn’t because of a hardware issue. Actually, the machine booted, but it would refuse to show the login screen after the initial load and the second appearance of the Apple logo. For the record, I had Mountain Lion installed on it and have had no problems so far. After trying some things like repairing disk permissions, clearing the NVRAM, do a safe boot and some other black magic suggested in the Apple support pages and a good friend who happens to know a lot about the Mac world, I came to the conclusion that the problem was really not repairable and decided to go for a clean Mountain Lion install.
After booting the box into a Ubuntu Live CD and backing up some non essential files that I’d rather not lose either, I reinstalled Mountain Lion. Everything was fine. I had now a clean Mountain Lion installation on a laptop without any noticeable hardware issues. I had just only lost some hours of my time. No big deal.
But then I went to the Mac App Store to redownload and reinstall iPhoto. To my surprise, the App did not appear as purchased. The system was asking me to pay the £13 or so it cost. The thing is, I had already purchased iPhoto 3 months ago. So I decided to email Apple support and ask for help.
This was the answer: “You purchased iPhoto when your Apple ID country was Spain, and then you changed your Apple ID country to United Kingdom, so you lost all purchases made while your ID was linked to Spain”. And this is in fact true: I moved from Barcelona to London 3 months ago and decided to change my Apple ID country to the UK. What I did certainly not know is that stupid policy of you losing all purchases when changing countries.
So I replied Customer Service to actually get a clarification on that, and the answer was crystal clear: “yes, all purchases in the App Store are linked to the country of your Apple ID, so if you change it, you lose the purchases”.
It seems this is no recent news, as a search on the internet showed different people having to deal with the same issue. But this did not make it less stupid. What kind on nonsense and stupid policy is that?
I could understand a similar policy with movies or music, as all those monster major distribution companies issue rights to watch or listen to certain material on a country basis. This is obviously a matter for another post and another site. But for software? And even worse, software being developed and sold by Apple themselves?
When did we all go so fucking crazy about everything?
So I asked Apple again: “are you telling me that I bought a software from you 3 months ago to run on this machine, and now, 3 months later, after having to do a system clean installation, on the same fucking machine, I have to pay AGAIN for the same fucking software?” The answer was clear again: “yes, I’m aware this is not the answer you were expecting but it’s how it works”. And then this hilarious predefined quote at the bottom of the email telling me “how happy we are to have you as a member of the Apple family”. Ha!
Searching on google again, I found out some people managed to get a refund because of that, so I thought I had nothing to lose to try. I emailed again (and did the same through the feedback links on Apple’s web site asking for a refund and telling them as nicely as I was able to do given the fucking circumstances that I felt like I was treated like garbage.
Let’s be honest. I am not one of those really old Apple customers. This MacBook was my second one and besides that I’ve only owned an iPod mini, two iPhones and an iPad (and I have to say the overall experience with both those products and the company was clearly positive). So no, I am not one of those poor sad bastards that go queue during the night to get a fucking gadget the day it gets released (although I have to admit I’ve done that with the World of Warcraft: The Burning Crusade release). But this really has nothing to do with it. They just crossed the line. Again. And yes, I know there is some shitty legal things involved in all this regarding VAT and some other things, but this is NOTHING Apple can not get over to make an App purchase valid if you fucking move countries.
In the end Apple resolved my issue by giving me some redeem codes, not only for iPhoto but also for iMovie and GarageBand (apps that I do not use and I’m very unlikely to do so in the future), but not because of what happened, according to the Customer Service email, but because “we have checked that the MacBook you bought came with iLife, so we are generous enough to let you fucking download again a software you already paid for 3 months ago”.
Well, you know what? You’ve lost a customer for a fucking £13 App.
It's no secret that Google Mail has become, over the last years, the most widely used email server and client on the world. Not only it's basically free, but with the use of Google Apps you can even use it on your own domains.
Because so many people use it, even system administrators, it may be good to know how to use it to send system emails. Also, because Ruby is actually the only scripting language I feel comfortable with, I'll show you a simple library to send emails using Google SMTP server as an outgoing server, so you don't have to configure your server with sendmail, postfix or another typical UNIX mail server.
The first thing we will need is to include (and install) two gems:
net/smtp (actually this comes from the Standard Library on Ruby 1.9)
tlsmail
The first one will allow us to use some SMTP features in Ruby, and the second one will allow us to use TLS authentication for SMTP, the method used by Google Mail.
With those two libraries, we can already send a simple email, using the standard SMTP format:
You can see here that the SMTP info is stored in a variable @smtp_info. We will take care of that later. Also, the variable mailtext passed to the method also needs a special format. More on that later as well. The really important fragment of code here is the one that calls enable_tls on the Net::SMTP module. This method is provided by the tlsmail gem and will allow our SMTP connection to use TLS as the authentication method. The other part of the code is pretty straightforward: we simply call the start method with a block, in which we actually send the email with send_message. Note that we have to provide the start method with the SMTP info of our Google Mail server account. This includes the server, which will be smtp.gmail.com, the port, which is 587, the HELO, which is gmail.com if using a standard account or your domain FQDN if using your own domain, and finally your username and password. For the authentication parameter we have to provide :plain (TLS will be used on top of that).
Now let's see how the mailtext string is built. In this case I'll be using a plain text format with two different variants: a simple text email, or an email with an attachment.
To send a simple text email, we have to follow the SMTP standard. I took the info from this tutorialspoint post. Here's the pattern we have to follow to build a compliant string:
defsend_plain_emailfrom,to,subject,bodymailtext=<<EOF
From: #{from}
To: #{to}
Subject: #{subject}#{body}EOFsend_emailfrom,to,mailtextend
Note the importance of the indenting here, as the from/to/subject lines must start at the first text column. With this simple method, you can then simply call the method we programmed before with the resulting string as a parameter and the email will be sent. Pretty easy.
Sending an attachment is a bit more complicated. As SMTP email is send in plain text, attachments are encoded in base64 strings, and are added to the message string in a special way. Here's how to do it in Ruby:
defsend_attachment_emailfrom,to,subject,body,attachment# Read a file and encode it into base64 formatbeginfilecontent=File.read(attachment)encodedcontent=[filecontent].pack("m")# base64rescueraise"Could not read file #{attachment}"endmarker=(0...50).map{('a'..'z').to_a[rand(26)]}.joinpart1=<<EOF
From: #{from}
To: #{to}
Subject: #{subject}
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary=#{marker}
--#{marker}EOF# Define the message actionpart2=<<EOF
Content-Type: text/plain
Content-Transfer-Encoding:8bit
#{body}
--#{marker}EOF# Define the attachment sectionpart3=<<EOF
Content-Type: multipart/mixed; name=\"#{File.basename(attachment)}\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename="#{File.basename(attachment)}"
#{encodedcontent}
--#{marker}--
EOFmailtext=part1+part2+part3send_emailfrom,to,mailtextend
As you can see, in the first place the file is read and converted to a base64 string. After that, the message is generated. SMTP uses a special unique marker to delimit the attachment from the rest of the text. In here we use the line (0...50).map{ ('a'..'z').to_a[rand(26)] }.join (extracted from StackOverflow) to generate a 50 char length random string. Although it's very unlikely to happen, we should check that this random string does not appear anywhere else in the message body or the base64 converted attached file before using it as a delimiter.
After that, the rest of the message is built, specifying it has an attachment and its delimiter in the following lines:
The file is actually attached some lines below. After that, we can pass this new string to the method that sends the email, and all done.
Now, because our SMTP info can be sensitive (it contains our username and our password), it might not be a good idea to just hardcode this info in the email sending script. That's why I've used a yaml serialized hash to store this info, so we can load it at any time. Doing this is really easy with the yaml gem:
smtp_info=beginYAML.load_file("/path/to/your/smtpinfo")rescue$stderr.puts"Could not find SMTP info"exit-1end
Now that we have all the parts programmed, we should only pack it a little so it can be of use as a library. The following code contains a simple script with a class to send the emails and a little program that reads parameters from the command line:
require'net/smtp'require'tlsmail'require'yaml'classSMTPGoogleMailerattr_accessor:smtp_infodefsend_plain_emailfrom,to,subject,bodymailtext=<<EOF
From: #{from}
To: #{to}
Subject: #{subject}#{body}EOFsend_emailfrom,to,mailtextenddefsend_attachment_emailfrom,to,subject,body,attachment# Read a file and encode it into base64 formatbeginfilecontent=File.read(attachment)encodedcontent=[filecontent].pack("m")# base64rescueraise"Could not read file #{attachment}"endmarker=(0...50).map{('a'..'z').to_a[rand(26)]}.joinpart1=<<EOF
From: #{from}
To: #{to}
Subject: #{subject}
MIME-Version: 1.0
Content-Type: multipart/mixed; boundary=#{marker}
--#{marker}EOF# Define the message actionpart2=<<EOF
Content-Type: text/plain
Content-Transfer-Encoding:8bit
#{body}
--#{marker}EOF# Define the attachment sectionpart3=<<EOF
Content-Type: multipart/mixed; name=\"#{File.basename(attachment)}\"
Content-Transfer-Encoding:base64
Content-Disposition: attachment; filename="#{File.basename(attachment)}"
#{encodedcontent}
--#{marker}--
EOFmailtext=part1+part2+part3send_emailfrom,to,mailtextendprivatedefsend_emailfrom,to,mailtextbeginNet::SMTP.enable_tls(OpenSSL::SSL::VERIFY_NONE)Net::SMTP.start(@smtp_info[:smtp_server],@smtp_info[:port],@smtp_info[:helo],@smtp_info[:username],@smtp_info[:password],@smtp_info[:authentication])do|smtp|smtp.send_messagemailtext,from,toendrescue=>eraise"Exception occured: #{e} "exit-1endendendif__FILE__==$0from=ARGV[1]to=ARGV[2]subject=ARGV[3]body=ARGV[4]attachment=ARGV[5]smtp_info=beginYAML.load_file(ARGV[0])rescue$stderr.puts"Could not find SMTP info"exit-1endmailer=SMTPGoogleMailer.newmailer.smtp_info=smtp_infoifARGV[4]beginmailer.send_attachment_emailfrom,to,subject,body,attachmentrescue=>e$stderr.puts"Something went wrong: #{e}"exit-1endelsebeginmailer.send_plain_emailfrom,to,subject,bodyrescue=>e$stderr.puts"Something went wrong: #{e}"exit-1endendend
And that's all! You can use the script as a standalone command to send an email with some command line arguments or just require it in your ruby script and use the class to send the messages.
Ruby on Rails performance is a topic that has been widely discussed. Whichever the conclusion you want to make about all the resources out there, the chances you'll be having to use a cache server in front of your application servers are pretty high. Varnish is a nice option when having to deal with this architecture: it has lots of options and flexibility, and its performance is really good, too.
However, adding a cache server in front of your application can lead to problems when the page you are serving has user dependent content. Let's see what can we do to solve this problem.
Some days ago I learnt about The FizzBuzz Test and did a simple implementation in Ruby. The FizzBuzz test is a simple algorithm that is supposed to do the following:
For each number from 1 to 100:
If the number is divisible by 3, print "Fizz"
If the number is divisible by 5, print "Buzz"
If the number is divisible by both 3 and 5, print "FizzBuzz"
Otherwise print the number
I was just reading about how you can use the Enumerator class to have generators in the Programming Ruby 1.9 book, and thought that a good implementation could be done using just an Enumerator, so here it is, along with a simple RSpect test:
require_relative'fizzbuzz'describeFizzBuzzdobefore(:all)do@fizzbuzzes=FizzBuzz.first(100)endit"returns 'Fizz' for all multiples of 3"do@fizzbuzzes[3-1].should=='Fizz'endit"returns 'Buzz' for all multiples of 5"do@fizzbuzzes[5-1].should=='Buzz'endit"returns 'FizzBuzz' for all multiples of 3 and 5"do@fizzbuzzes[60-1].should=='FizzBuzz'endit"returns the passed number if not a multiple of 3 or 5"do@fizzbuzzes[1-1].should==1endend
When you're developing an application in Rails (or Ruby), you spend lots of time in the IRB, the Interactive Ruby Shell. Usually just to test some Ruby code, start an application console or debug something going on inside the project. Yesterday, looking at a coworker screen, I saw he had his console with lots of color hints, and I thought it was pretty nice. I asked him about that and he told me he was using a special gem for that.
The gem is called wirble. It has some nice defaults and allows you to configure the colors as you wish. To use it in your consoles, just add this lines to your ~/.irbrc file:
If you ever try to run a GUI Java application when using xmonad as the Window Manager, you'll probably end up with a nice flat grey window where your buttons, toolbars and other desktop GUI goodies should be. I ran into that problem the other day when trying to evaluate the RubyMine Ruby on Rails IDE from which I heard such good things. After a rather painful installation of the official Java 6 JDK from Oracle in Ubuntu Lucid Lynx (which I'll write about in some other time), I managed to start up RubyMine just to find out I was seeing absolutely nothing on the screen.
Sometimes you need to use multiple databases in your Rails projects. Usually when some data must be shared between different applications. When this happens you usually have some models in a shared database, and some other models in the specific application database. This can be easily done using the establish_connection method in the shared models to tell them they have to connect to a different database.
However, when you need some interaction between those shared models and the models of your specific application, like a has_many, :through association, some problems arise. The typical Many To Many association uses an intermediate database table that links the relation between two models, and allows you to add some extra information on that relation. When navigating through the association, Rails tries to make an SQL query that joins the model with this intermediate table. For example, imagine you have a Team model, which has many Players, but a player can also be on more than one team. We use an intermediate model TeamPlayers (and we can also use it to save the role of that player into that team, for example). You would have those three tables:
teams
players
teams_players
When asking for the players of a given Team, Rails would do something similar to this:
SELECT"players".*FROM"players"INNERJOINteams_players" ON "players".id = "teams_players".player_id WHERE "players".team_id = 1
Where 1 is the id of the team you asked for. This [obviously] works perfectly fine when everything is in the same database, and it's as efficient as the SQL database manager you're using. What happens, however, when we have the Player model in another database? It will miserably fail because Rails will try to join with a table that doesn't exist.
Unfortunately, there's no efficient way to solve this problem, that is, using SQL, as you can't work with tables from different databases. However, there's a rather elegant solution that Brian Doll cared to implement as a gem a while ago. As indicated in the GitHub readme, you just have to use a has_many_elsewhere relation instead of the usual one, and make sure that the model referenced has the connection established to the shared database. And that's all.
The magic donde behind the scenes is pretty simple: this gem just replicates the same methods that the ActiveRecord::Base class does in the has_many method call, changing the failing unique SQL calls to double SQL calls, one for each database, fetching the intermediate models first, and then fetching the remote models using those ids.
This method is not perfect, as probably not all the goodness of the original association can be done with it, but for simple scenarios is more than enough.
Ubiquo is a Ruby on Rails, MIT Licensed Open Source CMS we develop and use at gnuine for a variety of projects. One of the features of Ubiquo is the ability to run jobs separately from the http requests to the site. Today I'm going to show you how to customize the Ubiquo Jobs plugin to create your own types of jobs and managers to launch them.
Sometimes can be useful to create different managers. An example of this situation is when you want to run different kind of jobs in different circumstances.
Ubiquo Jobs provides a default manager which will get ActiveJob jobs depending on priorities and schedule times:
defself.get(runner)recovery(runner)candidate_jobs=job_class.all(:conditions=>['planified_at <= ? AND state = ?',Time.now.utc,UbiquoJobs::Jobs::Base::STATES[:waiting]],:order=>'priority asc')job=first_without_dependencies(candidate_jobs)job.update_attributes({:state=>UbiquoJobs::Jobs::Base::STATES[:instantiated],:runner=>runner})ifjobjobend
The job_class variable defaults to UbiquoJobs::Jobs::ActiveJob. If you want to make your own manager to handle special jobs, or change the way the jobs are picked, the best way to do so is to implement your own manager. A nice rails-like way to do that is include them in the lib/ folder of your ubiquo project.
The class you should inherit from is UbiquoJobs::Managers::ActiveManager. If you wanted the manager to just pick up a specific subclass of ubiquo jobs, it would suffice to reimplement the self.job_class class method to return your own kind of job:
However, there’s a better way to do this. For this special case, the default UbiquoJob class provides a special member which stores the job’s class name, allowing you to select all objects subclasses of ActiveJob by its classname. For example, imagine you have a kind of job for special tasks that you know for sure will take a long time to complete. Seems reasonable to have a different manager to handle those jobs. You would create a new job in the file app/jobs/very_long_job.rb:
classVeryLongJob<UbiquoJobs::Jobs::ActiveJobdefdo_job_work#Do what needs to be done herereturn0endend
Then you could create a manager that handles only those kind of jobs by implementing your own subclass of the UbiquoJobs::Managers::ActiveManager class:
moduleJobManagersclassVeryLongJobManager<UbiquoJobs::Managers::ActiveManagerdefself.get(runner)recovery(runner)candidate_jobs=job_class.all(:conditions=>['planified_at <= ? AND state = ? AND type = ?',Time.now.utc,UbiquoJobs::Jobs::Base::STATES[:waiting],'VeryLongJob'],:order=>'priority asc')job=first_without_dependencies(candidate_jobs)job.update_attributes({:state=>UbiquoJobs::Jobs::Base::STATES[:instantiated],:runner=>runner})ifjobjobendendend
The code is exactly the same as the default ActiveManager class, but the finder will take an extra parameter, 'VeryLongJob', to indicate that only the ActiveJob objects that are of the subclass VerylongJob should be taken.
After that, you need to modify the task that calls the workers so it takes your manager, or create a new task that will run your manager. The default task that will
start a worker looks as this:
desc"Starts a new ubiquo worker"task:start,[:name,:interval]=>[:environment]do|t,args|options={:sleep_time=>args.interval.to_f}.delete_if{|k,v|v.blank?}UbiquoWorker.init(args.name,options)end
This uses a special configuration parameter to determine the manager to use. This configuration option is stored in Ubiquo::Config.context(:ubiquo_jobs), the name of the configuration option is :job_manager_class, and takes the manager class as a value. So in order to create a task that will use your manager, you should create a new task like this one:
desc"Starts a new ubiquo worker"task:start_very_long_jobs,[:name,:interval]=>[:environment]do|t,args|options={:sleep_time=>args.interval.to_f}.delete_if{|k,v|v.blank?}Ubiquo::Config.context(:ubiquo_jobs).set(:job_manager_class,JobManagers::VeryLongJobManager)UbiquoWorker.init(args.name,options)end
Your should call this task like this (assuming it’s on the same namespace as the default task):
One thing I find fascinating about Ruby is the fact that most common tasks are already programmed for you in its library. The Enumerable module is a clear example of that, providing you with lots of functionality to manipulate collections of objects.
One of those useful methods I discovered the other day was each_slice. This method allows you to iterate over the collection, just as each does, but lets you do it changing how many elements of the collection you get on each iteration. This is the example you can get from the documentation page:
You can see that from the original array from 1 to 10, on every iteration Ruby prints the numbers in groups of three, and the last one alone since the collection is not a multiple of 3. Now think about having to do this manually: it's not that hard, but its error prone and you have to do all that typical arithmetic logic that should be easy but never is. How handy that Ruby has already done that job for you.
This method is also pretty useful when working in Ruby on Rails. One simple example is when you have to manually implement some kind of pagination, or show a list of elements in columns or rows of fixed size: you have to simply iterate with each_slice and put the page/row/column logic on the block, and voilà.
I strongly suggest you take a look at the Enumerable module reference to take a look at all the other flavours of each methods it has and I'm sure you'll find all of them pretty useful in lots of situations!
If you ever wondered how to easily retrieve a random record in an ActiveRecord model, here’s en easy way to do that: use the sample method.
sample is a class method from the Array class that retrieves one or more random items from an array instance. It conveniently returns nil or an array lesser than the items requested if the original array has not enough items.
Since all ActiveRecordfinds return an array, you can easily add the sample call at the end of a find call to get the random items you need from complex queries.
For example, imagine you have a Book model which has a published_at datetime attribute and you want to show, in your library home page, a random selection of 5 books that have been published. You can easily get those using this snippet:
EDIT (30/11/2012): after revisiting this post I obviously found out that this is in fact a very inefficient way to get random records for large collections, as Rails will have to instantiate them all, then performing a random on them. Unfortunately, seems like the only way to get a true random collection of items is to perform the sort on the database engine and then getting the first n elements of the resulting query, which will also be slow for large collections. This can be done like this:
In this case we tell mySQL to sort the collection using the internal RAND() method. One problem with this solution is that it’s database-engine specific (the sorting method may be named different in other engines, and in fact at least in PostgreSQL is). Other solutions try to get pseudo random records using the id column, for example by getting the n first records which id is greater or lower than a certain number. While this may be ok in most cases (considering you use a random index to compare with based on the min and max for id values) it may not be so good in other cases.
If you encounter problems after upgrading Wordpress and the AddToAny plugin version .9.9.9.1 (the one I tested), try to update your footer.php file of your current theme too add this line just before the closing body tag:
<?phpwp_footer();?>
It seems that newer versions of the plugin put some javascript code into the footer section, so without this call, there's no javascript for AddToAny, and without javascript, you can't see the popup div that allows you to select the service you want to use to share your posts.
If you've ever used the serialize method in an ActiveRecord model, you may have faced the problem of writing a fixture for that particular serialized field. The serialize method is quite handy if you need to store a complex object (like a Hash or an Array) in a database field, without having to create additional models and relationships between them. A good example could be store the preferences of a user in a hash:
In order to do that, at the database table for the User class, among the other fields you'll need to add a text column for the preferences. After that, you can easily work with your model without too much of a hassle.
If you care to look at the rows of the model's table, you'll see that the serialized attribute is stored in YAML format:
sqlite> select preferences from users where id = 1;
---
:show_email: false
:allow_pm: false
Now, that if you need to add a fixture for your model that needs the preferences attribute to be set to a particular value? If you have to manually parse the value you want to put in there to be tested, it'll be a pain in the ass. Even if you have a script that converts certain values to YAML so you can copy and paste the script output to the fixture, it's not very comfortable. Hopefully, you have to remember that you can use some ERB magic in your fixtures :) So, here's the deal if you need to add something to the serializable attribute:
The to_yaml method converts the Hash into a YAML representation, and with inspect we convert that to a string. Using this technique, we can add whatever we want to a serialized field in our fixtures.
For some reason, the ArchLinux wiki is kind of outdated explaining how to install xmonad in Arch. Also, the new packages seem to have a bug and the xmonad installation won't work out of the box. Here you have detailed steps on how to install and run xmonad on ArchLinux.
First of all, you need to install the Xorg server. Refer to Xorg for detailed instructions. After that, you'll need to install the xmonad packages, named xmonad and xmonad-contrib.
pacman -Syu xmonad xmonad-contrib
This will install xmonad and all the required dependencies. After that, if you want a fairly simple X setup, add the line xmonad to your ~/.xinitrc file (hopefully you'll be using a display manager that uses that file like SLiM). If you try this on a freshly installed ArchLinux system, though, it won't work. There are some missing steps to do. First of all, you need to create the folder ~/.xmonad.
mkdir ~/.xmonad
After that, you need to create a new xmonad config file, called xmonad.hs</em into that folder, so fire up your favourite editor and fill the file with this basic (empty) configuration:
</p>
importXMonadmain=doxmonad$defaultConfig
Once you have you configuration file in place, it's time to rebuild xmonad:
xmonad --recompile
And that's all, you should be able to start your fresh new xmonad setup in ArchLinux. By the way, if you wonder why pressing Mod1 + Shift + Enter does nothing, make sure you have the package xterm installed.
If you develop a widget with Adobe AIR using HTML and Javascript, you may want to resize some elements of the HTML page depending on the size of the widget, thus having to resize them when the user decides to resize the widget. However, there's a little trick on using the RESIZE event of the air.Event object.
The trick is that when the event is raised, and you execute some method on the corresponding event handler, the widget won't have the correct size yet, so if you use the window.nativeWindow.width or window.nativeWindow.height values there you'll be getting erroneus results.
The solution is quite easy, though. You just have to let the HTML engine to adjust everything he needs to sort out the new sizes and get those attributes after that. How do you do that? By putting your code in a setTimeout call with 0 milliseconds timer. Here you can find an example (assuming use of jQuery):
$(document).ready(function(){window.nativeWindow.addEventListener(air.Event.RESIZE,onResize);});functiononResize(){varnativeWin=window.nativeWindow;setTimeout(function(){varwidth=nativeWin.width;varheight=nativeWin.height;},0);}//Here the values are correct
If you ever used autocomplete.ui plugin from jQuery UI and have an array with lots of suggestions you'll see that the solutions provided by the plugin are not always satisfactory. You can add a scrollbar to the suggestions box by using a CSS hack, but even with that, you'll have to render a big HTML that can be annoying on slow machines (mobile devices, for example).
I was working on a web site recently that had to be displayed on mobile devices and needed an autocomplete. But the suggestions array was big. A lot. This caused some problems on the mobile devices as they were behaving very slow, and the default plugin configuration doesn't allow you to specify a maximum number of items to show in the suggesstions box.
So I decided to do a dirty hack into the plugin code to add this behaviour, adding a max property to the options to be able to limit the number of suggestions to show.
It's not a perfect solution, because it should be implemented as a subclass or something, but if you need a fast solution, this is the way to go. You can find the code in my GitHub repository fork of jQueryUI. You can check the commit to see the changes I made.
I was developing an application recently that needed some king of horizontal bars to be drawn on a web page. I found the jQuery Progressbar plugin and found it it was something similar to what I wanted to achieve, so I took some spare time and modified it to convert it in a plugin I could use in my app. The result is the jQuery Bars plugin. It's a pretty simple plugin that will take a div and convert it into a horizontal bar, in which you can change the background color, the actual bar color, the duration of the animation and the height and width of the bar.
You can check a how it works and looks in this simple test I uploaded. It can be useful if you ever have to shown some kind of a percentage bar in a chart and you need a bit more customization that jQuery UI Progressbar gives you.
The plugin is dual licensed in MIT and GPLv2, the same license as jQuery, so feel free to use it or modify it at your will.
Today I was working on a web site that needs to retrieve some RSS feed over the internet. Since the web page has no server (HTML + javascript only) I couldn't access the feed from the server side. Also, because of the Cross Domain limitation of Ajax requests, I couldn't access the RSS in the client either. I searched Google for an API and found the Google Feed API, which does exactly what I want. However, because (I think) Google caches the RSS feed you request, there was a significant delay (about half an hour) between the update of the RSS contents and the RSS provided by Google (the feed was updated in a per minute basis, as it was a CoverItLive event). Seeing I couldn't access really recent posts from the feed using Google, I decided to implement my own RSS API using JSONP in a ruby on rails environment, since having an external server act as a proxy was allowed for the overall solution.
Basically you have to start creating a new controller that will handle the JSONP requests. In my case I just added a 'Feed' controller:
$ script/generate controller Feed
Then you edit the app/controllers/feed_controller.rb file and start coding. We will assume that the request will come in this form: http://server/feed/get?callback=some_callback&url=the_url_of_the_feed. Having this information, the controller code is pretty straightforward.
The first two lines are the requirements for the RSS module, which will allow us to parse a RSS feed. After that, we start with the get request. In there, we use the Net::HTTP.get() method, which will retrieve a URL content using a GET request and return its contents. To do so, we need to pass it an uri parameter, which we can get from the entire URL using the method URI.parse(). After this call, we have the XML of the RSS feed in url_contents. What we have to do now is build an RSS object with this XML. We'll do that by calling RSS::Parser.parse(). If you wish to do some modifications to the RSS contents, now is your change. In this simple example we'll simply bulk it all to the response.
To build the response, we need a JSON object. If everything went as expected, we can create a JSON object by simply creating a ruby associative array and calling the to_json method on it:
json={"error"=>false,"feed"=>rss}.to_json
If, on the contrary, we got an error (bad URL, bad RSS, whatever), we simply return the same JSON object with the error property set to true (that's done in the rescue clause).
After we have this JSON object built, we simply have to output the results. To do so, we use the help of a method called render_json which we have added to the controller code. In this method we simply output the JSON if we provide no callback (this means no JSONP), or either a padded JSON (hence the name JSONP) with the callback name followed by the JSON data. In either case we render the results as a js type.
For more detailed information on how JSONP works, check http://en.wikipedia.org/wiki/JSON#JSONP, but what you basically need to know is that when you do a JSONP request what you're really doing is retrieve a chunk of javascript code that will be run on your client, so be aware of the security issues you can have here.
If you've tried to install dropbox-nautilus from the source found in the <a href=http://www.dropbox.com>Dropbox</a> website, you'll find that you can't successfully complete the ./configure step of the package due to an error of the script not finding pygtk. This is an issue with Archlinux because of the way python binaries are handled in this distribution. However, you can use the AUR packages to install dropbox and its integration with Nautilus thank to the people that tweaked the scripts to work with Arch.
The first step you have to take is download the AUR packages. You'll need to download both dropbox and nautilus-dropbox. Save both .tar.gz files at you preferred location and uncompress them using this command:
tar xvfz <filename.tar.gz>
Obviously, change <filename.tar.gz> with the filenames you have downloaded. Each tar command will create a folder. Go to the dropbox folder and run this package:
makepkg -s
This will build a package and install the required dependencies while doing it if needed (it will ask for your root password if you're doing this without being root). If everything went ok, you'll find a file with the extension .xy in the folder you're in. This is what you need to install, using our beloved pacman (use sudo if you're not root):
pacman -U <filename.xy>
This will install dropbox. After this, do the same for the other package: nautilus-dropbox. makepkg -s, pacman -U <filaneme.xy> and you're done, you have Dropbox integrated with Nautilus. Just start Dropbox from your Applications menu and enjoy the service!
If you wonder how to make a GitHub (and other websites) like routes to access to hierarchical paths or files, here's the way to do it in ASP.NET MVC. GitHub is a GIT hosting service, and allows you to browse the repositories. When doing so, it uses a path as a routing parameter, as seen in this URL: https://github.com/erikzaadi/GithubSharp/blob/master/Core/Models/Commit.cs. This includes slashes and so to represent the directories, and is a parameter that depends on the file location inside the repository. A route like this can be done in ASP.NET using the called catch-all parameter.
The catch-all parameter allows you to use a wildcard on a route, so it takes everything after a given route as a single parameter. You can find the explanation of this feature in the ASP.NET Routing MASDN help page.
All you need to do to make a route like the one in the example to work is add this code to your Global.asax file, in the RegisterRoutes method:
This will pass the controller Blob a parameter called path that will contain the parameter you want (in the example that would be master/Core/Models/Commit.cs. All you have to do now is use this parameter as you wish so you can access the desired file and show it's contents on a web page.
If you've ever used the Ajax.BeginForm code to render a form in ASP MVC using Ajax (via jQuery, for example), you may have wondered there's an object you can pass to the call called AjaxOptions. This object allows you to pass the BeginForm call some interesting options to further enhance the form when it's rendered. One of those options is specially useful if you want some javascript to be executed just after the form has been rendered. You can always use the $(document).ready in jQuery, but this code will not be called if, for example, the form is rendered after a postback and you have some validation errors (a missing required field, for example). Fortunately, you can use the AjaxOptions object to tell the form to execute a method right after the form has been loaded (for the first time or after a postback).
Recently I started working in a project using MVC 2. I found out a very useful feature to retrieve JSON data from the server using an Action in a Controller.
This feature is in the base Controller class, which we inherit when we create a new controller. If you take a look into the different methods this class has you'll find those ones:
//// Summary:// Creates a System.Web.Mvc.JsonResult object that serializes the specified// object to JavaScript Object Notation (JSON).//// Parameters:// data:// The JavaScript object graph to serialize.//// Returns:// The JSON result object that serializes the specified object to JSON format.// The result object that is prepared by this method is written to the response// by the MVC framework when the object is executed.protectedinternalJsonResultJson(objectdata);
Along with this method, there are some overloads that allow more parameters, you can see them all in here: Controller.Json Method. In this example I'll use the first one, which is the simplest.
Today at work we found a bug. My workmate, not used to C#, usually uses the & operator to compare boolean values. However, in C#, the & operator does not use lazy evaluation.
One curious thing about C# is that it can use two different operators to calculate an and expression: the & operator and the && operator. The difference between both is that the first one (&) can be used both with integer types and boolean types. When used with integer types it will perform a bitwise comparison between the two, and when used with boolean values it will use the logical and operation between the two boolean values, evaluating all the parts of the expression. This means that using a code like this one:
will throw a runtime error if someObject is null, because it will try to obtain the SomeProperty value.
However, the && operator is only available to boolean expressions, and it uses lazy evaluation, this is, if the first condition evaluated is false, it will calculate false without evaluating the rest of the expression, because an and is only true if all the expressions are true.
Conclusion, be sure to always use && when evaluating boolean values if you want to avoid run time surprises :).
The Queue<T> class (and Stack<T> too) of the .NET Framework from Microsoft is implemented using an array. While this is a perfectly good approach, I think that a Linked List based implementation could be desired in some situations (specifically when the size of the queue is not fixed).
Since the implementation alone would be rather simple for a post, I’ll show you how to implement Unit Testing with the class using Nunit. Although this is a rather simple class to test I think it will show the basic concepts behind unit testing.
If you’ve ever worked with relatively large UpdatePanels maybe you’ll have had a problem: blocking the user some elements while the asynchronous postback is running. When working with local or LAN environments, the async responses might be fast, but over the internet, or on large calculations the async postback may take a while. During this period, you may want to block the UpdatePanel controls so the user can’t trigger another postback or do any other operations on that UpdatePanel. I’ll show you an easy way to do so by using the AJAX framework for .NET and jQuery and one of its plugins: blockUI.
For those who don’t know jQuery, it’s an opensource Javascript framework that is going to be embedded on future versions of Visual Studio. It’s a very good framework because of its simplicity and its extensibility, having lots of plugins. One of those plugins is the blockUI plugin, which allows you to block and unlock any part of the DOM at will.
One of the interesting new things on the .NET platform is the recent addition of Python and Ruby to the CLR. Both versions for .NET are called IronPython and IronRuby respectively, and they provide some new and good things to the platform.
Python and Ruby lovers will see now that they can use all the library and features of the .NET platform programming in their favorite scripting language. Since both of them are object oriented, you can now write fully fledged apps using either of them.
However, there's another interesting application for IronPython and IronRuby: adding scripting support for your existing .NET applications. This can be a very useful and powerful way to extend your applications and give the user freedom to program their own mini programs, scripts or whatever in your applications. It could be good for defining rules, assigning and calculating values, etc.
I'll provide a simple class you can use to add scripting to your application. I'll use IronPython in this example.
First of all, you have to download IronPython and install it, and add the references to the assemblies on your project references.
The usual way to proceed in those cases is to provide the user of some local variables you give them access to, execute the script, and then recover the values of those or new variables. To do so, You can use a class similar to this one:
usingSystem;usingSystem.Collections.Generic;usingSystem.Text;usingIronPython.Hosting;usingMicrosoft.Scripting.Hosting;usingMicrosoft.Scripting;namespaceScripting{internalclassPythonEngine{ScriptEnginem_engine;ExceptionOperationsm_exceptionOperations;SortedDictionary<string,object>m_inputVariables;stringm_script;internalPythonEngine(){m_engine=Python.CreateEngine();m_exceptionOperations=m_engine.GetService<ExceptionOperations>();}internalSortedDictionary<string,object>ScriptVariables{set{m_inputVariables=value;}}internalstringScript{set{m_script=value;}}internalExceptionOperationsExceptionOperations{get{returnm_exceptionOperations;}}internalSortedDictionary<string,object>Execute(){//Create structuresSourceCodeKindsc=SourceCodeKind.Statements;ScriptSourcesource=m_engine.CreateScriptSourceFromString(m_script,sc);ScriptScopescope=m_engine.CreateScope();//Fill input variablesforeach(KeyValuePair<string,object>variableinm_inputVariables){scope.SetVariable(variable.Key,variable.Value);}SortedDictionary<string,object>outputVariables=newSortedDictionary<string,object>();//Execute the scripttry{source.Execute(scope);//Recover variablesforeach(stringvariableinscope.GetVariableNames()){outputVariables.Add(variable,scope.GetVariable(variable));}}catch(Exceptione){stringerror=m_exceptionOperations.FormatException(e);//Do something with the pretty printed errorthrow;}returnoutputVariables;}}}
Usage of this class is pretty simple. You have to provide the object the script you want to execute and the input variables the script will have available as local variables. Once this is done, you have to call the Execute method, and this method will either return the output variables of the execution of the resulting script, or throw an exception.
SQL Server has a special extended stored procedure called xp_cmdshell. This procedure has a lot of power: it allows to execute any command line code on the machine hosting the SQL Server.
Imagine you want to list all the files on C: on the SQL Server Windows host: you could write a T-SQL statement like this one:
EXECUTEmaster..xp_cmdshell'dir c:'
This stored procedure, however, is a very dangerous one, as it would allow to execute harmful code. This is the reason why it's disabled by default. Even when enabled, only users on the sysadmin role can use it.
If you ever need some users the ability to run only some specific commands with xp_cmdshell, you can use the method I'll explain below, making use of the EXECUTE AS modifier of the stored procedure definitions in T-SQL.
This morning I was working on a project at work. It's a Web Application using the ASP .NET 2.0 framework and C# as a code behind language. My friend Ioannis came over to see what was I doing and when he saw I was appending some strings together he asked me this question: "are you using a StringBuilder to use those strings?". And I replied with this answer: "no, I am not". This kind of stupid dialog came over because last week we were discussing about using StringBuilders instead of the default String class operators to append strings each other in Java. It seemed using the StringBuilder class resulted in an overall performance gain. It was then when I asked: "don't tell me this happens with C#, too?". And he answered: "yes, it does!".
This week we had a bug report of one of our products regarding some strange deadlocks in our database access. For those of you who don't know what a deadlock is, I'll try to summarize here what a transaction is in a relational database environment and why those transactions might lead to those nasty errors, and try to explain what was causing this deadlock in our SQL Server 2005 engine.
One of the deficiencies of actual programming languages, specially those ones still widely used that are old, such as C or C++, is that they were designed having in mind the sequential programming paradigm. This usually means that those languages don't have standard ways to work with multithreading features, and you usually have to rely on third party libraries to develop thread safe software.
Today I'll be discussing a design pattern called Double Check, which can be widely used to manage the resource access, elimination and initialization in a safe thread way.
Suppose you have an iPod. Now suppose your music library size is by far bigger than your iPod memory. This is not an unusual situation, specially if your iPod is a Shuffle, Mini or Nano version, since the ones able to play videos usually have much more memory.
Now suppose you're a busy person or simply don't have the time to select what music you'll want to hear every morning before going to work, so sitting in front of your iTunes program and selecting what you thing you're in the mood to hear is out of the question. But of course, the chances you want to listen to different music from yesterday is high. And because you are a pragmatic geek, you're trying to find a way to perfectly update your iPod music to fit your needs automatically.
When I decided to buy my first Apple Computer, a MacBook, some months ago, I was planning on using it as a Media Center, connecting it to my HD Ready TV. And one of the features that I expected to use the most with it was the FrontRow. However, I was a little disappointed on the lack of configuration options you have on that software, specially when playing movies (I found it extremely useful anb beautiful for iTunes and iPhoto integration).
One of the first problems I encountered was with some codecs. FrontRow uses the QuickTime player, and that program seem to have some problems with video formats. I had to install some third party plugins for it to be able to play such a [now] standard video format as WMV. Another big problem I found was the lack of subtitle rendering option. English is not my native language, and although I'm improving every day, I often need to have my English spoken videos bundled with subtitles that come in external files such as SRT or SUB files. As far as I know, QuickTime player does not have support to render those files.
So one of the features I expected to use on my MacBook was ruined for some of those reasons, because using another video player in a FrontRow style was impossible... until I found Sofa Control. I'm not the kind of man to believe in the typical company "mottos", but I firmly believe in this one: "Applications that should have been in the box". This is the motto of CASE Apps, people responsible of Sofa Control, and I have to absolutely agree with them.
Sofa Control is a software that takes out the best use of the new Mac Family Remote Controls, which allow you to use FrontRow. Sofa Control goes further and allows you to absolutely control almost every typical piece of software for Mac OS, including some popular video players such as VLC, the one I use on Mac OS and one that supports almost every video coden and has builtin subtitle support. With Sofa Control you can use you remote to play/stop/resume multimedia files, slide pages on PowerPoint, Keynote or PDF presentations, use it as a virtual mouse moving with the control arrows, and a lot more. This is exactly what you need to simply be able to fully control your Mac when you're laying on your bed or your sofa. The perfect software for lazy people like me! And it has a builting script manager to allow you to write your own scripts for new applications.
The only thing I miss from it it's that it's not free, but it costs only $14.95, and to be honest, it's worth the price.
The virtualization world is not only for Windows and its name is not only VMWare. Specially since the migration of Apple's Macs to the Intel x86 platform, that kind of software has seen in the Cupertino computers a new and fresh market to exploit. And one of the software pieces who has built one of the best virtuaization products for the Macs has been Parallels Desktop.
Altough the Windows virtualization offered by Parallels is pretty nice (I'm still impressed of the Coherence Mode and I can't wait to test the new 3D support features of the last version), it has also support for other Operating Systems such as Linux. And because Ubuntu is at this moment one of the most popular Linux distributions, a lot of people (including myself) have tried to install it in a virtual image on a Mac.
Unfortunately, the latest Ubuntu version, 7.04, aka Feisty Fawn, seems to have some problems installing on Parallels. The most important one is that the Live and installer CD will simply not boot correctly, showing a "Black Screen of Death" when loading the frame buffered splash screen.
But don't worry, everything should be fine if you choose Solaris and Other Solaris as a OS Type and OS Version respectively when creating the virtual machine. Simply boot the Live CD, install the Linux distribution and when it asks you to reboot, shut down, change the virtual machine type to Linux and "Other 2.6 Linux" and it's done! Enjoy the wonderful open source operating system on your Mac OS!
If you've been assigned to a new web application project lately, you'll probably have had to deal with this [not] new AJAX technology. To be honest, AJAX is good, and websites like Google Mail and Flickr are good examples of that. But remember something: it's always bad to abuse of something. It's always bad to abuse AJAX. Don't use it if it doesn't really make sense to do it, and if your boss insists on it, ask him if he would use truck wheels on his BMW.
If you begin to have a lot of computers at home, or even you manage a little LAN on an office, it may come in handy to have a little domain configured. Having a domain configured has some advantages, including easy machine naming and name resolution of those machines. We'll explain here how to setup a little domain with a linux machine and an opensource DHCP and DNS servers.
In the developing process of applications that are not as small as the typical "Hello, World!" examples, there are a variety of factors than can lead to important time savings.
There's a lot of documentation out there on how to design and specify application before the coding process starts, but there is a crucial factor on success that is not usually spoken of: the way you manage, create and edit your source files.
And of course there are some beautiful software pieces to help developers in that process. They're called IDEs (Integrated Development Environment).
The problem with most of those IDEs is that they offer so many options that you usually have to read a user's manual to really take the best from them. Ok, this is something normal, you might say. Maybe you're right, but be honest, how many software user guides have you read in your life? And I'm not talking about the usual RTFM for a linux man page which can be 4 pages long at most. I'm talking about a user's manual of 500 pages. I haven't.
And that's the reason today I'll be talking about a nice feature I found on one of the most powerful IDEs out there (regardless of being from Microsoft): Visual Studio 2005 Code Snippets.
What is Think in Geek, you may ask. Well, the obvious answer is simple: a geek blog. We could have named it Yet Another Geek Blog, but we couldn't find a nice domain for that name (yagb.com sucks hard). And why another geek blog, you may ask too? The answer is another question: why not? Or, if you prefer it: If others have their geek blog, we want one, too!
Talking seriously (although what has been said until now it's true, too), this is a space were we want to simply share our thoughts and knowledge about the geek world in general and the IT world in particular. We simply love those topics, and after having visited thousands of other web places where we have found some interesting tips or solutions to common problems, we though the best way to thank that was precisely to give back what we got to the community.
So feel free to enjoy our thoughts, to find answers to problems we've already solved before, or simply to know what other people (we and people who want to contribute with comments) thinks about particular things about the geek world.