Walk-through flang – Part 3
In the last chapter we saw how the driver handles the compilation and how it invokes flang1 and flang2. In this chapter we are going to start with flang1.
Documentation
Flang comes with some decent documentation that is worth reading it. It is not built by default unless we pass -DFLANG_INCLUDE_DOCS=ON to the cmake command. It is originally written in nroff but fortunately there is a nroff→reStructured Text tool which is then used by sphinx to generate readable HTML files. Needless to say that you will need sphinx installed for that last step. Once built, you will find the documentation in STAGEDIR/build-flang/docs/web/html.
flang1
According to the documentation flang1 is called the front-end or in the driver "the upper" (i.e. higher level) part of flang. Its task is basically parsing the Fortran code and generating an Abstract Syntax Tree (AST). Then there are two lowering steps applied to that AST and finally it is emitted in a form called ILM.
The parsing process is long and involved so in this chapter we will focus on the lexing (scanning) of the input. We will talk about the (syntactical) parsing itself in the next chapter.
Initialization
flang1 and flang2 are written in C90 and they use a lot of global variables. This is usually undesirable in new codebases, specially if you plan to make flang part of a library, but not uncommon in ancient codebases. A common pattern you will see in the code is that it reinitializes some globals or restores them from previously kept values.
main
The main function of flang1 is found in flang/tools/flang1exe/main.c and the function init is invoked to initialize the front end. If you wonder what getcpu does, you'll be a bit disappointed as the name is misleading: it is just a function to measure time (a stopwatch function).
1554
1555
1556
1557
1558
1559
1560
1561
1562
1563
/** \brief Fortran front-end main entry
\param argc number of command-line arguments
\pram argv array of command-line argument strings
*/
int
main(int argc, char *argv[])
{
int savescope, savecurrmod = 0;
getcpu();
init(argc, argv); /* initialize */
Function init does a few things but basically parses the arguments, in argc and argv, and initializes the scanner.
Parsing the arguments is done in two steps. First a set of accepted command options is registered in an argument parser structure. The registration specifies the kind of command option expected and what variable to update when the option is encountered. For instance, maybe you recall in part 2 that we saw that the preprocessing was done by flang itself. This is controlled by a command option called preprocess that acts as a boolean: its presence in the command line options means that we want to preprocess the input file. Once all the command options have been registered, then argc and argv are effectively parsed, which updates the variables we specified. So the rest of the file is basically checking that what was specified in the command line makes sense.
Variable preproc below is a global variable defined in main.c. Variable flg is a global data structure containing all sorts of fields regarding the compilation flags of flang. We will often encounter another global variable called gbl which contains global information for the whole front end.
This function is rather long so I'm just showing some representative parts.
static void
init(int argc, char *argv[])
{
// (.. omitted ..)
/* Initialize the map that will be used by dump handler later */
create_action_map(&phase_dump_map);
arg_parser_t *arg_parser;
create_arg_parser(&arg_parser, true);
/* Register two ways for supplying source file argument */
register_filename_arg(arg_parser, &sourcefile);
register_string_arg(arg_parser, "src", &sourcefile, NULL);
/* Output file (.ilm) */
register_combined_bool_string_arg(arg_parser, "output", (bool *)&(flg.output),
&outfile_name);
// (.. omitted ..)
register_boolean_arg(arg_parser, "preprocess", &arg_preproc, true);
// (.. omitted ..)
register_boolean_arg(arg_parser, "freeform", &arg_freeform, false);
// (.. omitted ..)
/* Set values form command line arguments */
parse_arguments(arg_parser, argc, argv);
// (.. omitted ..)
if (was_value_set(arg_parser, &arg_preproc)) {
/* If the argument was present on command line set the value, otherwise
* keep "undefined" -1 */
preproc = arg_preproc;
}
if (was_value_set(arg_parser, &arg_freeform)) {
/* If the argument was present on command line set the value, otherwise
* keep "undefined" -1 */
flg.freeform = arg_freeform;
}
// (.. omitted ..)
if ((gbl.srcfil = fopen(sourcefile, "r")) != NULL) {
/* fill in gbl.src_file, file_suffix */
char *s;
gbl.src_file = (char *)malloc(strlen(sourcefile) + 1);
strcpy(gbl.src_file, sourcefile);
basenam(gbl.src_file, "", sourcefile);
file_suffix = "";
for (s = gbl.src_file; *s; ++s) {
if (*s == '.')
file_suffix = s;
}
goto is_open;
}
/* not found */
error(2, 4, 0, sourcefile, CNULL);
}
is_open:
// (.. omitted ..)
scan_init(gbl.srcfil);Scanner initialization
The scanner is initialized by scan_init found in tools/flang1/flang1exe/scan.c. It first registers all the Fortran keywords.
/** \brief Initialize Scanner. This routine is called once at the beginning
of execution.
\param fd file descriptor for main input source file
*/
void
scan_init(FILE *fd)
{
sem.nec_dir_list = NULL;
/* for each set of keywords, determine the first and last keywords
* beginning with a given letter.
*/
init_ktable(&normalkw);
init_ktable(&logicalkw);
init_ktable(&iokw);
init_ktable(&formatkw);
init_ktable(¶llelkw);
init_ktable(&parbegkw);
init_ktable(&deckw);
init_ktable(&pragma_kw);
init_ktable(&ppragma_kw);
init_ktable(&kernel_kw);
// ..
curr_fd = fd;
curr_line = 0;
first_line = TRUE;
in_include = FALSE;
gbl.eof_flag = FALSE;</p> All Fortran keywords start with a letter and flang groups them in several categories depending on the context in which they can appear. There are 10 tables, one per category. </p>
- Normal keywords, found at the beginning of regular Fortran statements like
WHILE,IF,DO,PROGRAM, etc. - Keywords that appear inside logical-expressions like
.and.,.eqv.,.true.,.not., etc. - Specifiers, mainly I/O statements but for other statements that have specifiers (like ALLOCATE). Examples of this are
UNIT,ERR,FMT, etc. - Specifiers of the FORMAT statement. In Fortran the FORMAT statement is the equivalent of the printf format string, but rather than a string literal containing specific values the FORMAT statement specification is part of the programming language syntax. Given its syntax, though, the FORMAT statement is a beast of its own. Keywords in this category include
EN,ES,X, etc. - Keywords that start OpenMP directives like PARALLEL or TASK. Given that OpenMP allows combining many directives, the scanner has to take into account cases like
target teams distribute parallel do simdas a special token (we will see below why). - Keywords that appear inside OpenMP directive as clauses. These are things like
FIRSTPRIVATE,SHAREDorSIMDLEN. - Flang supports many extensions, one of them is the
CDEC$directives, or specific pragmas of PGI Fortran. There are three categories for keywords used by these extensions.
Each keywords is represented using a KWORD type. The third field (nonstandard) does not seem used at least when the keywords are registered.
20
21
22
23
24
typedef struct {
char *keytext; /* keyword text in lower case */
int toktyp; /* token id (as used in parse tables) */
LOGICAL nonstandard; /* TRUE if nonstandard (extension to f90) */
} KWORD;
Then 10 arrays follow with the keywords of each category.
static KWORD t1[] = { /* normal keyword table */
{"", 0}, /* a keyword index must be nonzero */
{"abstract", TK_ABSTRACT},
{"accept", TK_ACCEPT},
{"align", TK_ALIGN},
{"allocatable", TK_ALLOCATABLE},
{"allocate", TK_ALLOCATE},
{"array", TKF_ARRAY},
{"assign", TK_ASSIGN},
{"associate", TK_ASSOCIATE},
{"asynchronous", TK_ASYNCHRONOUS},
{"backspace", TK_BACKSPACE},
...
static KWORD t2[] = { /* logical keywords */
{"", 0}, /* a keyword index must be nonzero */
{"a", TK_AND, TRUE},
{"and", TK_AND, FALSE},
{"eq", TK_EQ, FALSE},
{"eqv", TK_EQV, FALSE},
...
static KWORD t3[] = {
/* I/O keywords and ALLOCATE keywords */
{"", 0}, /* a keyword index must be nonzero */
{"access", TK_ACCESS},
{"action", TK_ACTION},
{"advance", TK_ADVANCE},
{"align", TK_ALIGN}, /* ... used in ALLOCATE stmt */
{"asynchronous", TK_ASYNCHRONOUS},
...
These arrays are then registered in their table of type KTABLE (note that for some reason unknown to me there is no t10 array, instead it is t11).
typedef struct {
int kcount; /* number of keywords in this table */
KWORD *kwds; /* pointer to first in array of KWORD */
/* the following members are filled in by init_ktable() to record
* the indices of the first and last keywords beginning with a
* certain letter. If first[] is zero, there does not exist a
* keyword which begins with the respective letter. A nonzero
* value is the index into the keyword table.
*/
short first[26]; /* indexed by ('a' ... 'z') - 'a' */
short last[26]; /* indexed by ('a' ... 'z') - 'a' */
} KTABLE;
...
static KTABLE normalkw = {sizeof(t1) / sizeof(KWORD), &t1[0]};
static KTABLE logicalkw = {sizeof(t2) / sizeof(KWORD), &t2[0]};
static KTABLE iokw = {sizeof(t3) / sizeof(KWORD), &t3[0]};
static KTABLE formatkw = {sizeof(t4) / sizeof(KWORD), &t4[0]};
static KTABLE parallelkw = {sizeof(t5) / sizeof(KWORD), &t5[0]};
static KTABLE parbegkw = {sizeof(t6) / sizeof(KWORD), &t6[0]};
static KTABLE deckw = {sizeof(t7) / sizeof(KWORD), &t7[0]};
static KTABLE pragma_kw = {sizeof(t8) / sizeof(KWORD), &t8[0]};
static KTABLE ppragma_kw = {sizeof(t9) / sizeof(KWORD), &t9[0]};
static KTABLE kernel_kw = {sizeof(t11) / sizeof(KWORD), &t11[0]};Source forms
Fortran is a very old language that was born in the context of punch cards. Each punch card can represent only 72 or 80 (or sometimes 132) characters. By default a single punch card represented a single statement. Sometimes, though, we will run off of space in a punch card and we need to continue on the next one. To tell whether the next punch card was a continuation of the previous one, a special mark is used in some part of the punch card. Nowadays Fortran is written in computers using text editors, not punch cards, so each line of text has the content of a punch card. This means that it is possible to continue a statement to the next line, because the length restrictions still exist. Fortran limits to 19 continuations. This is, a statement can be up to 20 lines. At this point of the initialization, we allocate enough space for those 20 lines.
 Card from a Fortran program: Z(1) = Y + W(1). Source: Wikipedia
Card from a Fortran program: Z(1) = Y + W(1). Source: Wikipedia
{kind=link}
In the code below stmtbefore is the global variable that will contain the character buffer of the whole statement before a process called crunch (that we will see later what it means). The statement, crunched or not, will be found in the character buffer stmtb.
/*
* Initially, create enough space for 21 lines (1 for the initial card,
* 19 continuations, and an extra card to delay first reallocation until
* after the 20th card is read). Note that for each line, we never copy
* more than 'MAX_COLS-1' characters into the statement -- read_card()
* always locates a position after the first (cardb[0]) position.
* read_card() also terminates a line with respect to the number of columns
* allowed in a line (flg.extend_source)
* More space is created as needed in get_stmt.
*/
max_card = INIT_LPS;
stmtbefore = sccalloc((UINT)(max_card * (MAX_COLS - 1) + 1));
if (stmtbefore == NULL)
error(7, 4, 0, CNULL, CNULL);
stmtbafter = sccalloc((UINT)(max_card * (MAX_COLS - 1) + 1));
if (stmtbafter == NULL)
error(7, 4, 0, CNULL, CNULL);
stmtb = stmtbefore;
last_char = (short *)sccalloc((UINT)(max_card * sizeof(short)));
if (last_char == NULL)
error(7, 4, 0, CNULL, CNULL); Lines, i.e. cards, may have two source forms: fixed form and free form. All lines of a single file usually use one of the source forms but some compilers allow changing the source form inside a file and mixing the two source forms in a single file.
Until Fortran 90, the only possible form was fixed form. Fixed form mimics the layout used in Fortran punch cards: columns 1 to 5 represent a numerical label and the statement is written from columns 7 to 72. If character 6 is a character other than a space (or a zero) it means that this line is a continuation of the previous one and columns 1 to 5 should be blanks. Columns beyond the 73 are ignored in a regular or continuated line. Other blanks, except when found inside string literals (called "character context") are not significant in fixed form (e.g ABC is the same as A BC or AB C). Also this form recognizes as comment lines, that are ignored by the compiler, those lines that have a C, * or (as en extension) D in column 1, or the character ! in columns 1 to 5.
2 0 I F( A.G T.1 0)T
AH EN; P R I NT
**, "A is bigger than 10"
E NDI F
The other source form, free form, is closer to modern programming languages syntax. There are no column restrictions, except for the length of the line. Spaces are relevant and continuations are marked using a & at the end of the statement and optionally another & at the beginning of the next statement (in this second form the statement is pasted as if there was nothing between the two ampersand characters). A comment starts after a ! character (outside of "character context) in any column of the line.
20 IF (A .GT. 10) THEN
PRINT *, "A is bigger than 10"
END IF
At this point the variable flg.freeform states if the input source form is free form or not. As we commented in last chapter files like .f, .F, .for, .FOR will be assumed by the driver to be fixed form by default. The function set_input_form is used to switch between each mode. When the mode is set a couple of pointer to functions will be updated: p_get_stmt and p_read_card. They point to get_stmt and get_card for fixed form and to ff_get_stmt and ff_get_card in free form.
Now the initialization of the scanner is complete and we can proceed to read the first card. To do this we invoke p_read_card. We will revisit this part later but for now it is suffice to know that the card buffer always contains the card from which we are going to get the statement. So before we can get the statement, the card has to be read. Because of this flow we need to read the first card here.
card_type = (*p_read_card)();Program units
Once the scanner has been initialized the initialization is mostly complete and then flang1 proceeds to parse each program unit.
Fortran code, at the top level, are a sequence of program units. Each program unit is independent of the others. There are 5 kinds of program units in Fortran: PROGRAM, SUBROUTINE, FUNCTION, MODULE and BLOCK DATA. PROGRAM is what in C is considered the main function. There must be a single PROGRAM program unit a Fortran program. SUBROUTINE and FUNCTION program units define extern procedures, meaning that these procedures are defined at the global level of the program. A module system was added to Fortran as of Fortran 90, and it is represented by the MODULE program units. MODULE program units have two parts: non-executable and executable. The non-executable part defines types, global variables or generic specifiers (a form of overloading). The executable part is used to define module procedures which are FUNCTION or SUBROUTINE (sub)program units contained in the MODULE. BLOCK DATA is a weird program unit to initialize a special kind of global data called named COMMON blocks and is seldomly used today.
Parsing is structured in flang1 as an interaction of two components: the scanner and the parser. The scanner is responsible of reading the lines (cards) and tokenizing the input. The parser will check that the sequence of tokens provided by the scanner has the form (but not necessarily the correct meaning) of a valid Fortran program. Parsing is done by the function parser() invoked in a loop inside main, once per program unit.
Parsing: high level overview
Parsing is done in two steps. A first step parses only non-executable statements. The second parses the executable statements. Fortran has a relatively strict ordering of statements and they are classified as either non-executable or executable (except ENTRY statement that has to be both due to its special nature, but let's ignore this). Non-executable statements intuitively are declarations, and in principle do not entail code generation as they only impact the symbol tables and such (this is a bit theoretical because they do impact code generation). Executable statements are imperative statements in the code. Both phases are performed by the _parser function (invoked from parser twice)
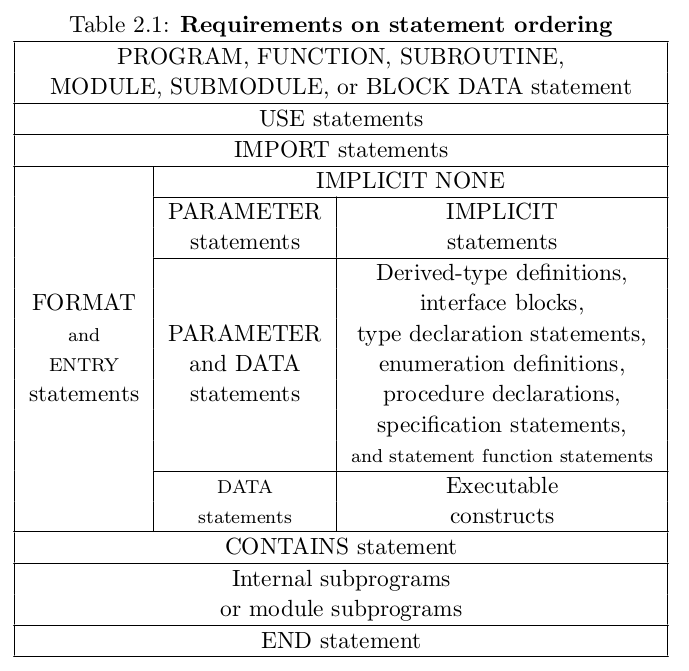 Ordering of statements in Fortran 2008. Columns in a row mean that the statements can be interspersed with the other statements in the other columns of the row. Source: Fortran 2008 draft
Ordering of statements in Fortran 2008. Columns in a row mean that the statements can be interspersed with the other statements in the other columns of the row. Source: Fortran 2008 draft
Before it parses anything the parser needs a token. This is done by invoking get_token. Depending on the semantic phase get_token will invoke _get_token or _read_token. The first one works using the input file. The second works in an intermediate file that is generated during the first phase.
Let's focus first in the first phase. When _get_token is invoked it checks if the global variable currc is NULL. If it is it means that we have to read the next statement. To do this it invokes p_get_stmt (that we set up above when we initialized the scanner by calling set_input_form).
Reading a statement
The pointer to function p_get_stmt will either point to get_stmt, for fixed form, or ff_get_stmt, for free form. Both functions will read all the lines that form the current statement, at least one, into the stmtb buffer. A requirement of this function is that at least one card has been already read before we can copy its contents. This requirement is fulfilled the first time we call them because we did this when we initialized the scanner above. It also implies that we have to make sure the next card has been read before we invoke this function again. The function itself (or one of the functions it calls) makes sure this happens before leaving.
If the statement spans to more than one line, because of continuations, we need to read the next line. In fixed form this is done relatively straightforward in the code, once we have read the current line we read the next card, if the next card is a continuation we just keep looping and reading the next card. A schema of the code (because the original is a bit too long) follows:
static void
get_stmt(void)
{
do {
switch (card_type) {
case CT_INITIAL: // This means a normal card
// Pad line to 72 characters and copy to stmtb
// Also handle the label field and put it in scn.
break;
case CT_CONTINUATION: // This card continues the previous one
// Copies from the character next to the continuation column to the end of the line
// (Continuation column is usually column 6 but because of extensions it can be column 2)
break;
case CT_COMMENT:
// Do nothing
break;
// other cases here
}
card_type = read_card();
} while (card_type == CT_CONTINUATION ||
card_type == CT_COMMENT);
));
}
In free form, things are a bit more complicated. Continuations are specified using a & at the end of the current line and optionally another & in the next line. At the top level the schema is similar to the one used in fixed form but a function ff_prescan is used to handle the & symbols. That function basically copies the characters in the line to stmtb but has a special case for &, when it finds a & then it has to advance to the next line skipping comments that may appear and being careful if a & appears as the first nonblank of the next line. This last step is handled by ff_get_noncomment which will read the next cards as needed: at least one but can be more than one if there are comments.
Now the statement has been read and is found in stmtb.
Reading cards
One of the operations that are needed when reading a statement is reading the cards (or lines). The functions dat to this are read_card, fixed form, and ff_read_card, free form. Calling these functions returns the kind of the card read as we've seen above each card has an associated card kind. The whole set is shown below.
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
/* define card types returned by read_card: */
#define CT_NONE 0
#define CT_INITIAL 1
#define CT_END 2
#define CT_CONTINUATION 3
#define CT_SMP 4
#define CT_DEC 5
#define CT_COMMENT 6
#define CT_EOF 7
#define CT_DIRECTIVE 8
#define CT_LINE 9
#define CT_PRAGMA 10
#define CT_FIXED 11
#define CT_FREE 12
#define CT_MEM 13
/* parsed pragma: */
#define CT_PPRAGMA 14
#define CT_ACC 15
#define CT_KERNEL 16
The first thing both functions do when reading a card is to invoke _readln. This function will read a whole line of the input file and put it in the cardb array. Then the function uses this buffer to process the current card (recall card means line in this context).
212
213
214
static char cardb[CARDB_SIZE]; /* buffer containing last card read
* in. text terminated by newline
* character. */
A card of CT_INITIAL means the first card related to a statement. CT_EOF is used to notify that we have reached the end of the file. The scanner checks if a line is of the form # number "filename", if so it return CT_LINE. If a line only contains blanks is handled as a comment of type CT_COMMENT.
In fixed form, then it checks if the first column has a character % or $, if so this card is a CT_DIRECTIVE. If the first characters are C$OMP, *$OMP or !$OMP then this is an OpenMP directive in which case the card will be of kind CT_SMP. Similarly for Cuda Fortran C$CUF, *$CUF or !$CUF but the card type is CT_KERNEL. If the line started with C, * or ! but did not match any directive or supported pragma, again the whole card will be a CT_COMMENT. If the whole line is just the characters END then it will be CT_END. This is sort of a special case because the Fortran standard explicitly says that a END statement cannot be continuated.
In free form similar checks happen but without checking columns and taking into account the different form of continuations. A line that starts with a non-blank & will be a CT_CONTINUATION. Similar checks like the ones done for fixed form are done for the cases of CT_SMP, CT_KERNEL, etc.
Constructing the token
As we explained above _get_token invokes p_get_stmt to read a statement which in turn will read a card. At this point stmtb contains the full statement. Global variable currc points to the next character to be read in the statement. If it is NULL, as explained above, we have to read the statement.
static int
_get_token(INT *tknv)
{
static int lparen;
tknval = 0;
retry:
if (currc == NULL) {
scnerrfg = FALSE;
put_astfil(FR_STMT, NULL, FALSE);
stmtb = stmtbefore;
if (!scn.multiple_stmts) {
(*p_get_stmt)();
}
/* ... */Crunch
Now currc points to the first character in the statement and we can start reading it. Before we proceed, though, we may have to crunch the statement.
/* ... */
if (no_crunch) {
no_crunch = FALSE;
currc = stmtb;
sig_blanks = FALSE;
} else {
crunch();
stmtb = stmtbafter;
/* ... */
All statements, except pragma lines starting with $PRAGMA, are crunched. The variable no_crunch, set during p_get_stmt will state that. In practice it is always false so we will crunch almost every statement. Crunch normalizes the input statement so it is easier to handle by the scanner.
- In free form the label of the statement, if any, is processed.
- Blanks and tabs are removed. In fixed form this means removing all blanks (except those in character context) and in free form remove all unnecessary ones. In free form redundant sequences of blanks are removed (e.g. two consecutive blanks).
- Upper case letters are passed to lowercase. This is because in Fortran technically the basic character set does not include lowercase letters so there is no case-sensitivity by default in identifiers (if wanted it must be provided by the vendor).
- Character strings (like
"ABC") are added to the symbol table. Registering a string in the symbol table assigns it an integer identifier (unless it was already registered, in which case the same identifier is used). The whole character string is replaced by the byte 31 followed by the 4 bytes of the integer on the symbol table encoded in big endian (first byte found is the most significant byte). - Similarly for integer constants that are not decimals (like
B'0101',O'644'orX'FFF') the initial character, B, O or X, is replaced by the bytes 22, 28 and 29 respectively though the rest of the constant is left as is.
Crunch also checks that parentheses are well balanced in the statement. It also computes the free (or exposed in flang parlance) of comma (,), a double colon (::) or an equal sign (=) or arrow (=>). Here free means not found inside parentheses. The reason to do this is because of the way Fortran statements have to be parsed. Fortran keywords are not reserved words, so they can be used as valid identifiers. All Fortran statements, except assignment statements, start with a keyword. This puts us in a weird position as nothing prevents an assignment statement to start with a keyword as well. The following rules are used:
- If there is a free equal sign this can be an assignment statement like
A = expr. This is stated in the global variableexp_equal. Note that a case likeIF (A < 3) B = 4has a free equal sign and will have to be handled specially. - Similarly, if there is a free arrow this can be a pointer assignment statement like
P => expr. This is stated in the global variableexp_ptr_assign. - If there is a free comma this cannot be an assignment. Usually this is a
DOstatement likeDO I = 1, 100. This is stated in the global variableexp_comma. In fixed form a very similar syntax likeDO I = 1. 100would beDOI=1.100which would be an assignment statement. - If there is a free double colon this cannot be an assignment either. Something like
INTEGER :: A = 3. Note that in fixed form, where blanks are not significantINTEGER A = 3would be the same asINTEGERA=3which would be an assignment statement.
Once we know something is not a statement then we can expect a keyword as the first thing, otherwise any identifier (including one that could be a keyword) is to be expected.
The code assumes that a function
IF has been declared, with four dummy arguments THEN, ENDIF, DO and ENDDO. It also assumes that two user-defined operators .ELSE. and .WHILE. havee been declared too.
RECURSIVE FUNCTION IF(THEN,ENDIF,DO,ENDDO) RESULT (ELSE)
USE IMPLICIT
IMPLICIT INTEGER(REAL) (A-Z)
IF (THEN < 10) ELSE = THEN .ELSE. DO
IF (THEN > 10) THEN
ELSE = IF(THEN=1,ENDIF=1,DO=1,ENDDO=1)
ELSE
ELSE = .WHILE. 4
ENDIF = 3
ENDIF
DO WHILE = DO, DO + DO
ENDDO = WHILE + ENDDO
ENDDO
END FUNCTION IF
The crunched statement is kept in stmtbafter and stmtb is updated to point to it (the original statement as read from the input is still available in stmtbefore).
Tokenization
Now the token can be tokenized. First the scan initializes some more state at this point. The flag scnerrfg is set to true if crunch failed (e.g. parentheses were not balanced) and in some other points where the scanner routines find problems. In these cases the parser is preventively reinitialized (as it could happen that the error happens in the middle of a statement) and the whole statement is ignored.
/* ... */
crunch();
stmtb = stmtbafter;
if (scnerrfg) {
parse_init();
goto retry;
}
scn.id.avl = 0;
currc = stmtb;
scmode = SCM_FIRST;
ionly = FALSE;
par_depth = 0;
past_equal = FALSE;
reset_past_equal = TRUE;
acb_depth = 0;
bind_state = B_NONE;
/* ... */
At this point several special cases are handled first for statements that start with !$DEC, !$OMP, !$PRAGMA, etc. Let's ignore them and focus on the usual scanning. The code now proceeds to a big switch that handles every character in the input. The outcome of this switch is basically a value stored in tkntype, an integer that states the kind of token we have found in the input.
If we find a blank we ignore it and restart the switch (which at its switching condition has the side effect of moving to the next character already). A semicolon (;) is used in Fortran to have more than one statement per line (though only the first statement can have label), in this case we need to remember if this line has multiple statements (in order to avoid requesting a new statement when entering _get_token in case currc is NULL) and then we return the token "end of line" (TK_EOL). Returning a token is done by jumping to the label ret_token (which does return the token and something else, as we'll see below).
/* ... */
again:
switch (*currc++) {
case ' ':
goto again;
case ';': /* statement separator; set flag and ... */
scn.multiple_stmts = TRUE;
case '!': /* inline comment character .. treat like end
* of line character ....... */
case '\n': /* return end of statement token: */
currc = NULL;
tkntyp = TK_EOL;
goto ret_token;
/* ... */
Next cases tokenize identifiers invoking the alpha function.
/* ... */
case 'a':
case 'b':
/* ... */
case 'z':
case 'A':
case 'B':
/* ... */
case 'Z':
case '_':
case '$':
if ((scmode == SCM_IDENT) && (bind_state == B_RESULT_RPAREN_FOUND)) {
scmode = SCM_FIRST;
}
alpha();
break;Function alpha first gathers all the characters that can form up an identifier or keyword. Unfortunately, this function is giant and is written in a very difficult style to explain. So I will try to summarise what it does rather than pasting here the code.
- Gather all the characters that can form up an identifier.
- If we are at the beginning of a statement then we proceed to identify the keyword
- There are a couple of special cases handled here for type parameters
LENandKIND. They can only occur inside aTYPEconstruct. - Now check if the initial identifier could actually be a statement whose form is a keyword followed by a (. These are
ASSOCIATEandSELECT TYPE(including theSELECTTYPEspelling). If the checks succeed eitherTK_ASSOCIATEorTK_SELECTTYPEis already returned. - Now check if a free equal sign for the cases where it may not designate an assignment expression, cases like
IF(A > B) C=10. Similarly for cases likeIF(A > B) P=>expr - If there is a free double colon that could be a
USEkeyword in statements of the formUSE INTRINSIC :: foo. - At this point check the keyword, if it is not just return an identifier, otherwise return the keyword found.
Returning the keyword found is done by jumping to the label get_keyword. It starts by invoking the function keyword. This function checks the first letter of the current scanned keyword in a given keyword table (in this case the table of normal keywords of Fortran). Recall that the keyword tables are indexed by the first letter of the keyword. Using this letter we get a range of known keywords (that start with that letter). These known keywords are sorted alphabetically. Function cmp returns 0 if an exact match is found, otherwise it returns a negative or positive number depending on whether the current token is lexicographically lower or greater, respectively. This is why once we see that the scanned keyword is no higher than the current known keyword, we can stop checking because no match will actually be found.
Note that the parameter exact is not used at all in this function.
5964
5965
5966
5967
5968
5969
5970
5971
5972
5973
5974
5975
5976
5977
5978
5979
5980
5981
5982
5983
5984
5985
5986
5987
5988
5989
5990
5991
5992
5993
5994
5995
5996
5997
5998
5999
6000
6001
6002
6003
6004
6005
/* return token id for the longest keyword in keyword table
* 'ktype', which is a prefix of the id string.
* Set 'keylen' to the length of the keyword found.
* Possible return values:
* > 0 - keyword found (corresponds to a TK_ value).
* == 0 - keyword not found.
* < 0 - keyword 'prefix' found (corresponds to a TKF_ value).
* If a match is found, keyword_idx is set to the index of the KWORD
* entry matching the keyword.
*/
static int
keyword(char *id, KTABLE *ktable, int *keylen, LOGICAL exact)
{
int chi, low, high, p, kl, cond;
KWORD *base;
/* convert first character (a letter) of an identifier into a subscript */
chi = *id - 'a';
if (chi < 0 || chi > 25)
return 0; /* not a letter 'a' .. 'z' */
low = ktable->first[chi];
if (low == 0)
return 0; /* a keyword does not begin with the letter */
high = ktable->last[chi];
base = ktable->kwds;
/*
* Searching for the longest keyword which is a prefix of the identifier.
*/
p = 0;
for (; low <= high; low++) {
cond = cmp(id, base[low].keytext, keylen);
if (cond < 0)
break;
if (cond == 0)
p = low;
}
if (p) {
keyword_idx = p;
return base[p].toktyp;
}
return 0;
}
In case no keyword is found (though we somehow expected one) or we directly expected an identifier, then alpha will jump to the label return_identifier. This part of the code still has to do some extra checks, because some keywords might appear in special cases like an array constructor of the form (/ REAL :: 1.2, 3.4 /).
After these initial checks then the code can really return an identifier of type TK_IDENT in the tkntype global variable. Identifiers also have a value kept in the global variable tknvalue. The global variable scn has a field scn.id which is basically a resizeable buffer of chars with a couple of fields scn.id.avl (available) and scn.id.size (what has been allocated). The buffer itself, scn.id.name, is reallocated as needed. Basically the identifier is appended to the buffer and then the index in the buffer of the just appended identifier is used as the tknvalue. This buffer is reused for each statement so it keeps only the identifiers found in the current statement. Also note that an identifier that appears more than once in a statement (like B = A + A) will be appended twice and each occurrence will have a different tknvalue. This schema may look a bit naive but works well if, as happens often, just a few identifiers are used in a statement.
For integer and real constants the function called is get_number. This function can handle both integers or reals. For integers several atoi-like functions are used to get the value of the designated integer constant. For reals strtod is used (apparently there is no support for reals bigger than C's double). Once the value has been computed then it is signed in in a hash table of constants. This is done using the getcon function which returns a new symbol identifier in the symbol table. We will see the symbol table in a later chapter.
Finally once the current token has been scanned it is passed to _write_token. This function basically writes the token into an intermediate file. This file is used in the second step of parsing the input.
The intermediate file
We mentioned above that the parsing is done in two steps. The first step constructs the tokens directly from the Fortran input file. This token is then returned to the parser, which will use it to update its internal state machine that checks the validity of the token sequence. But as a side effect of _get_token, tokens, along with some payload info, are written in an intermediate file. This intermediate file is used by _read_token when retrieving tokens for the second step of the parsing (recall that the parser calls get_token and in the second step get_token calls _read_token, in the first it called _get_token which we have described above). Basically the code is parsed twice (two passes) but each time the input is different and each pass obviously does slightly different things. We will see parsing with more detail in the next chapter.
We may wonder the reason of this design. My hypothesis is that flang is based on an ancient codebase that was first written in an era where computers had much less memory than today. In a more modern design the interaction between the two passes would probably involve structures in memory. This approach does not work well if memory is scarce. An option also could be just reusing the original input, but we've already seen that Fortran complicates reading the input so scanning twice the input seems wasteful in terms of time. That said, due to the nature of Fortran seems unavoidable having to do two passes in order to fully parse the code.
It is not trivial to view this intermediate as a temporary unnamed file is used but hacking scan_init can be used to get what is written in this file. This file contains a set of records, each record started by a record identifier of 4 bytes. They are defined in scan.h.
/* File Records:
*
* Each record in the ast source file (astb.astfil) begins with a
* 4-byte type field. In most cases, the remaining portion of the
* field is textual information in the form of a line (terminated by
* '\n'.
*/
#define FR_SRC -1
#define FR_B_INCL -2
#define FR_E_INCL -3
#define FR_END -4
#define FR_LINENO -5
#define FR_PRAGMA -6
#define FR_STMT -7
#define FR_B_HDR -8
#define FR_E_HDR -9
#define FR_LABEL -98
#define FR_TOKEN -99As stated by the code itself, each record is usually followed by text. Consider the following input.
PROGRAM MAIN
INTEGER :: A, B
A = 1
B = 2
C = A + &
A + B
PRINT *, "HELLO WORLD"
PRINT *, C
END PROGRAM MAINGenerates the following intermediate file, which I have processed because some of the fields are encoded directly as binary data.
FR_SRC: 'test.f90'
FR_STMT: 1 'PROGRAM MAIN'
FR_LINENO: '1'
FR_TOKEN: '463 0 PROGRAM'
FR_TOKEN: '56 0 4 main <id name>'
FR_TOKEN: '321 0 END'
FR_STMT: 2 ' INTEGER :: A, B'
FR_LINENO: '2'
FR_TOKEN: '383 0 INTEGER'
FR_TOKEN: '37 0 ::'
FR_TOKEN: '56 0 1 a <id name>'
FR_TOKEN: '17 0 ,'
FR_TOKEN: '56 2 1 b <id name>'
FR_TOKEN: '321 0 END'
FR_STMT: 3 ' A = 1'
FR_LINENO: '3'
FR_TOKEN: '56 0 1 a <id name>'
FR_TOKEN: '174 0 ='
FR_TOKEN: '60 1 1 <integer>'
FR_TOKEN: '321 0 END'
FR_STMT: 4 ' B = 2'
FR_LINENO: '4'
FR_TOKEN: '56 0 1 b <id name>'
FR_TOKEN: '174 0 ='
FR_TOKEN: '60 2 2 <integer>'
FR_TOKEN: '321 0 END'
FR_STMT: 5 ' C = A + &'
FR_LINENO: '5'
6 ' A + B'
FR_TOKEN: '56 0 1 c <id name>'
FR_TOKEN: '174 0 ='
FR_TOKEN: '56 2 1 a <id name>'
FR_TOKEN: '16 0 +'
FR_TOKEN: '56 4 1 a <id name>'
FR_TOKEN: '16 0 +'
FR_TOKEN: '56 6 1 b <id name>'
FR_TOKEN: '321 0 END'
FR_STMT: 7 ' PRINT *, "HELLO WORLD"'
FR_LINENO: '7'
FR_TOKEN: '458 0 PRINT'
FR_TOKEN: '14 0 *'
FR_TOKEN: '17 0 ,'
FR_TOKEN: '169 629 11 48454c4c4f20574f524c44 <quoted string>'
FR_TOKEN: '321 0 END'
FR_STMT: 8 ' PRINT *, C'
FR_LINENO: '8'
FR_TOKEN: '458 0 PRINT'
FR_TOKEN: '14 0 *'
FR_TOKEN: '17 0 ,'
FR_TOKEN: '56 0 1 c <id name>'
FR_TOKEN: '321 0 END'
FR_STMT: 9 'END PROGRAM MAIN'
FR_LINENO: '9'
FR_TOKEN: '333 0 1 ENDPROGRAM'
FR_TOKEN: '56 0 4 main <id name>'
FR_TOKEN: '321 0 END'
FR_SRC is used to specify the file name. FR_STMT is used to mark the beginning of the next statement. Its payload is the line number of the statement and the text of the statement (before crunching). A record FR_LINENO is used to set the line number of the tokens next tokens, the payload is the line number itself. Unfortunately if the statement spans onto more than one line no new FR_LINENO is emitted so the diagnostics are always emitted from the first line of the statement. Each token is represented by a FR_TOKEN record. The payload contains at least two integers: the type of token first and then some value associated to the token type (if not relevant for the type of token this value is zero). Most tokens are just followed by the text of the token and sometimes some description of the kind of token like <quoted string> or <id name> that as far as I understand have no purpose other than making debugging easier.
It is interesting to analyse some tokens with more detail:
FR_TOKEN: '169 629 11 48454c4c4f20574f524c44 <quoted string>'
This is basically a token that is just the string literal. The first two integers are the token type, the token value (the hash that was computed during crunch but it is not valid any more in this pass so it will be unused) and the length of the token and then a sequence of hexadecimal digits representing the bytes of the string. In this particular case the string HELLO WORLD (48 is H, 45 is E, 4c is E, etc.)
FR_TOKEN: '56 2 1 a <id name>'
FR_TOKEN: '16 0 +'
FR_TOKEN: '56 4 1 a <id name>'
This is a sequence of three tokens. The first and last one are a token of kind TK_IDENT (56) as we mentioned above their token value is unique inside the statement (even if the token is the same identifier). The second token is simply the token for the plus sign (+).
FR_STMT: 5 ' C = A + &'
FR_LINENO: '5'
6 ' A + B'
This is interesting because flang assumes that any record that is not a known record (as defined above in scan.h) is a line number. This is why all the record kind identifiers are negative numbers. So what is emitted for a statement that spans in several lines is just the record of the statement with the first line (followed by a FR_LINENO) and then another line number and a statement string.
The function _read_token only returns when encounters a record of kind FR_TOKEN. The other register kinds do not have any effect (like FR_SRC) or just have side-effects for the parser itself (like FR_STMT or FR_LINENO).
Wrap-up
Ok. This post is already too long so maybe we should stop here. But first a summary:
- Parsing is done in two steps (or passes).
- The parser asks tokens to the scanner.
- Depending on the parsing step, the scanner uses a different origin to form the tokens that returns to the parser.
- The first step uses the Fortran source file.
- This involves reading the whole statement.
- To read the whole statement one or more cards (lines) have to be read.
- Once the statement is read it is crunched in which a few tokens are simplified
- The tokens are returned using that crunched statement.
- As a side-effect of returning the tokens, an intermediate file is generated.
- The second step uses the intermediate file.
- The intermediate file is just a sequence of records.
- Records that encode tokens are used to return tokens to the parser.
In the next chapter we will see with more detail the parser, now that we understand where tokens come from.